DE Pathway Analysis
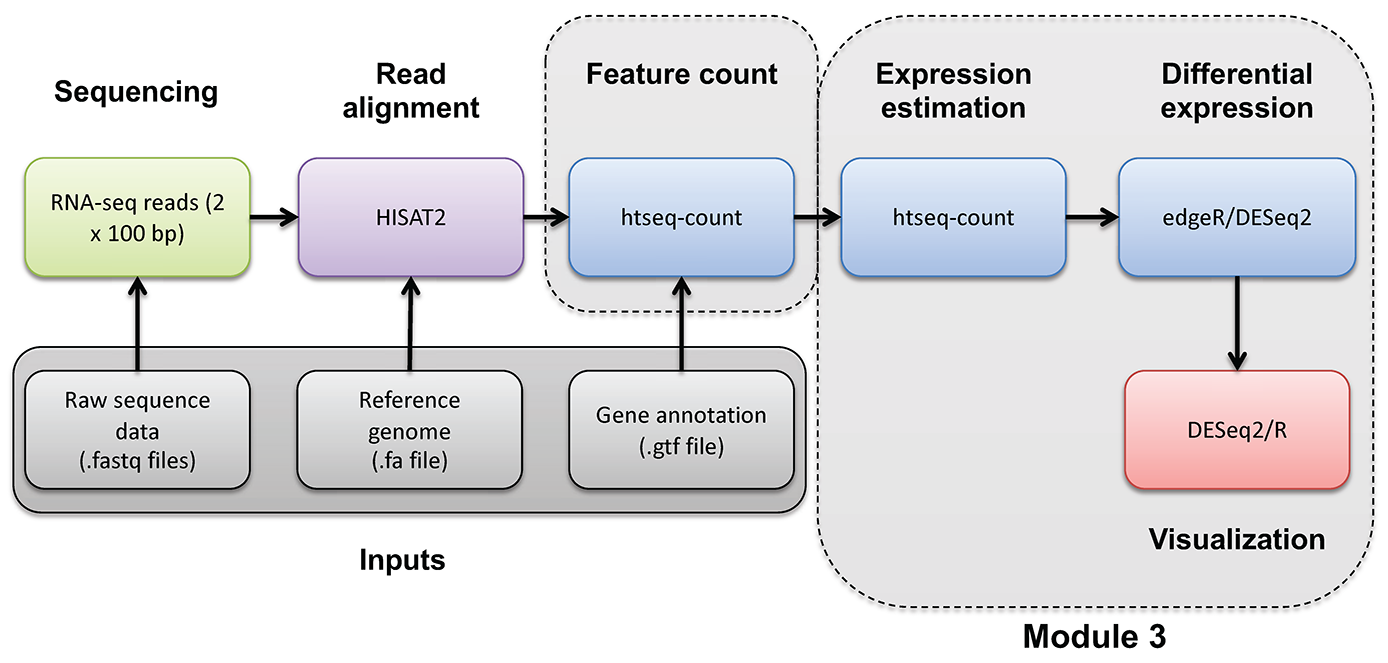
In this section we will use the GAGE tool in R to test for significantly enriched sets of genes within those genes found to be significantly “up” and “down” in our UHR vs HBR differential gene expression analysis. Do we see enrichment for genes associated with brain related cell types and processes in the list of DE genes that have significant differential expression beween the UHR samples compared to the HBR samples?
What is gage?
The Generally Applicable Gene-set Enrichment tool (GAGE) is a popular bioconductor package used to perform gene-set enrichment and pathway analysis. The package works independent of sample sizes, experimental designs, assay platforms, and is applicable to both microarray and RNAseq data sets. In this section we will use GAGE and gene sets from the “Gene Ontology” (GO) and the MSigDB databases to perform pathway analysis.
Importing DE results for gage
Before we perform the pathway analysis we need to read in our differential expression results from the previous DE analysis.
# Define working dir paths and load in data
datadir = "/workspace/rnaseq/de/htseq_counts/deseq2"
# datadir = "/cloud/project/outdir/"
setwd(datadir)
# Load in the DE results file with only significant genes (e.g., https://genomedata.org/cri-workshop/deseq2/DE_sig_genes_DESeq2.tsv)
DE_genes = read.table("DE_sig_genes_DESeq2.tsv", sep = "\t", header = TRUE, stringsAsFactors = FALSE)
output_dir = "/workspace/rnaseq/de/htseq_counts/deseq2/pathway/"
# output_dir = "/cloud/project/outdir/pathway/"
if (!dir.exists(output_dir)) {
dir.create(output_dir, recursive = TRUE)
}
setwd(output_dir)
Now let’s go ahead and load GAGE and some other useful packages.
library(AnnotationDbi)
library(org.Hs.eg.db)
library(GO.db)
library(gage)
Setting up gene set databases
In order to perform our pathway analysis we need a list of pathways and their respective genes. There are many databases that contain collections of genes (or gene sets) that can be used to understand whether a set of mutated or differentially expressed genes are functionally related. Some of these resources include: GO, KEGG, MSigDB, and WikiPathways. For this exercise we are going to investigate GO and MSigDB. The GAGE package has a function for querying GO in real time: go.gsets(). This function takes a species as an argument and will return a list of gene sets and some helpful meta information for subsetting these lists. If you are unfamiliar with GO, it is helpful to know that GO terms are categorized into three gene ontologies: “Biological Process”, “Molecular Function”, and “Cellular Component”. This information will come in handy later in our exercise. GAGE does not provide a similar tool to investigate the gene sets available in MSigDB. Fortunately, MSigDB provides a download-able .gmt file for all gene sets. This format is easily read into GAGE using a function called readList(). If you check out MSigDB you will see that there are 8 unique gene set collections, each with slightly different features. For this exercise we will use the C8 - cell type signature gene sets collection, which is a collection of gene sets that contain cluster markers for cell types identified from single-cell sequencing studies of human tissue.
# Set up go database
go.hs = go.gsets(species = "human")
go.bp.gs = go.hs$go.sets[go.hs$go.subs$BP]
go.mf.gs = go.hs$go.sets[go.hs$go.subs$MF]
go.cc.gs = go.hs$go.sets[go.hs$go.subs$CC]
# Here we will read in an MSigDB gene set that was selected for this exercise and saved to the course website.
c8 = "https://genomedata.org/rnaseq-tutorial/c8.all.v7.2.entrez.gmt"
all_cell_types = readList(c8)
Annotating genes
OK, so we have our differentially expressed genes and we have our gene sets. However, if you look at one of the objects containing the gene sets you’ll notice that each gene set contains a series of integers. These integers are Entrez gene identifiers. But do we have comparable information in our DE gene list? Right now, no. Our previous results use Ensembl IDs as gene identifiers. We will need to convert our gene identifiers to the format used in the GO and MSigDB gene sets before we can perform the pathway analysis. Fortunately, Bioconductor maintains genome wide annotation data for many species, you can view these species with the OrgDb bioc view. This makes converting the gene identifiers relatively straightforward, below we use the mapIds() function to query the OrganismDb object for the Entrez id based on the Ensembl id. Because there might not be a one-to-one relationship with these identifiers we also use multiVals="first" to specify that only the first identifier should be returned. Another option would be to use multiVals="asNA" to ignore one-to-many mappings.
DE_genes$entrez = mapIds(org.Hs.eg.db, column = "ENTREZID", keys = DE_genes$ensemblID, keytype = "ENSEMBL", multiVals = "first")
Some clean-up and identifier mapping
After completing the annotation above you will notice that some of our Ensembl gene IDs were not mapped to an Entrez gene ID. Why did this happen? Well, this is actually a complicated point and gets at some nuanced concepts of how to define and annotate a gene. The short answer is that we are using two different resources that have annotated the human genome and there are some differences in how these resources have completed this task. Therefore, it is expected that there are some discrepencies. In the next few steps we will clean up what we can by first removing the ERCC spike-in genes and then will use a different identifier for futher mapping.
#Remove spike-in
DE_genes_clean = DE_genes[!grepl("ERCC", DE_genes$ensemblID), ]
##Just so we know what we have removed
ERCC_gene_count = nrow(DE_genes[grepl("ERCC", DE_genes$ensemblID), ])
ERCC_gene_count
###Deal with genes that we do not have an Entrez ID for
missing_ensembl_key = DE_genes_clean[is.na(DE_genes_clean$entrez), ]
DE_genes_clean = DE_genes_clean[!DE_genes_clean$ensemblID %in% missing_ensembl_key$ensemblID, ]
###Try mapping using a different key
missing_ensembl_key$entrez = mapIds(org.Hs.eg.db, column = "ENTREZID", keys = missing_ensembl_key$Symbol, keytype = "SYMBOL", multiVal = "first")
#Remove remaining genes
missing_ensembl_key_update = missing_ensembl_key[!is.na(missing_ensembl_key$entrez),]
#Create a Final Gene list of all genes where we were able to find an Entrez ID (using two approaches)
DE_genes_clean = rbind(DE_genes_clean, missing_ensembl_key_update)
#Reduce to only the unique set of entrez genes in case different genes were mapped to the same entrez ID using the two approaches
DE_genes_clean=DE_genes_clean[!duplicated(DE_genes_clean$entrez),]
Final preparation of DESeq2 results for gage
OK, last step. Let’s format the differential expression results into a format suitable for the GAGE package. Basically this means obtaining the log2 fold change values and assigning entrez gene identifiers to these values.
# grab the log fold changes for everything
De_gene.fc = DE_genes_clean$log2FoldChange
# set the name for each row to be the Entrez Gene ID
names(De_gene.fc) = DE_genes_clean$entrez
Running pathway analysis
We can now use the gage() function to obtain the significantly perturbed pathways from our differential expression experiment.
Note on the abbreviations below: “bp” refers to biological process, “mf” refers to molecular function, and “cc” refers to cellular process. These are the three main categories of gene ontology terms/annotations that were mentioned above.
#Run GAGE
#go
fc.go.bp.p = gage(De_gene.fc, gsets = go.bp.gs)
fc.go.mf.p = gage(De_gene.fc, gsets = go.mf.gs)
fc.go.cc.p = gage(De_gene.fc, gsets = go.cc.gs)
#msigdb
fc.c8.p = gage(De_gene.fc, gsets = all_cell_types)
###Convert to dataframes
#Results for testing for GO terms which are up-regulated
fc.go.bp.p.up = as.data.frame(fc.go.bp.p$greater)
fc.go.mf.p.up = as.data.frame(fc.go.mf.p$greater)
fc.go.cc.p.up = as.data.frame(fc.go.cc.p$greater)
#Results for testing for GO terms which are down-regulated
fc.go.bp.p.down = as.data.frame(fc.go.bp.p$less)
fc.go.mf.p.down = as.data.frame(fc.go.mf.p$less)
fc.go.cc.p.down = as.data.frame(fc.go.cc.p$less)
#Results for testing for MSigDB C8 gene sets which are up-regulated
fc.c8.p.up = as.data.frame(fc.c8.p$greater)
#Results for testing for MSigDB C8 gene sets which are down-regulated
fc.c8.p.down = as.data.frame(fc.c8.p$less)
Explore significant results
Alright, now we have results with accompanying p-values (yay!).
What does “up-“ or “down-regulated” mean here, in the context of our UHR vs HBR comparison? It may help to open and review the data in your DE_genes_DESeq2.tsv file.
Look at the cellular process results from our GO analysis. Do the results match your expectation?
#Try doing something like this to find some significant results:
#View the top 20 significantly up- or down-regulated GO terms from the Cellular Component Ontology
head(fc.go.cc.p.up[order(fc.go.cc.p.up$p.val),], n = 20)
head(fc.go.cc.p.down[order(fc.go.cc.p.down$p.val),], n = 20)
#You can do the same thing with your results from MSigDB
head(fc.c8.p.up)
head(fc.c8.p.down)
#What if we want to know which specific genes from our DE gene result were found in a specific significant pathway?
#For example, one significant pathway from fc.go.cc.p.down was "GO:0045202 synapse" with set.size = 22 genes.
#Let's extract the postsynapse DE gene results
synapse = DE_genes_clean[which(DE_genes_clean$entrez %in% go.cc.gs$`GO:0045202 synapse`),]
#How many total synapse genes are there in GO? How many total DE genes? How many overlap?
length(go.cc.gs$`GO:0045202 synapse`)
length(DE_genes_clean$entrez)
length(synapse$entrez)
#Are the synapse DE genes consistently down-regulated? Let's print out a subset of columns from the DE result for synapse genes
synapse[,c("Symbol", "entrez", "log2FoldChange", "padj", "UHR_Rep1", "UHR_Rep2", "UHR_Rep3", "HBR_Rep1", "HBR_Rep2", "HBR_Rep3")]
More exploration
At this point, it will be helpful to move out of R and further explore our results locally. We will use an online tool to visualize how the GO terms we uncovered are related to each other.
write.table(fc.go.cc.p.up, "fc.go.cc.p.up.tsv", quote = FALSE, sep = "\t", col.names = TRUE, row.names = TRUE)
write.table(fc.go.cc.p.down, "fc.go.cc.p.down.tsv", quote = FALSE, sep = "\t", col.names = TRUE, row.names = TRUE)
Visualize
For this next step we will do a very brief introduction to visualizing our results. We will use a tool called GOView, which is part of the WEB-based Gene Set Ananlysis ToolKit (WebGestalt) suite of tools.
Step One
-
Use a web browser to download your results
-
For AWS: Navigate to the URL below replacing YOUR_IP_ADDRESS with your amazon instance IP address: https://YOUR_IP_ADDRESS/rnaseq/de/htseq_counts/deseq2/pathway
-
Download the linked files by right clicking on the two saved result files:
fc.go.cc.p.up.tsvandfc.go.cc.p.down.tsv. -
For posit Cloud: Navigate to the
outdir/pathwayfolder in the ‘Files’ pane. Selectfc.go.cc.p.up.tsvandfc.go.cc.p.down.tsvthen ‘More’ -> ‘Export…’. You may need to unzip the downloaded files. -
Open the result file in your text editor of choice. We like text wrangler. You should also be able to open the file in excel, google sheets, or another spreadsheet tool. This might help you visualize the data in rows and columns (NB: There might be a small amount of formatting necessary to get the header to line up properly).
-
You can either create an input file using this file as a guide, or you can simply use your downloaded data to cut and paste your GO terms of interest directly into GOView.
Step Two
- Navigate to the WEB-based Gene Set Analysis ToolKit (WebGestalt)
Step Three
-
Navigate to the GOView tool
-
Then, input the GO terms you would like to explore into the GOView interface by following the steps described in the “Beginning an analysis” section of the webpage. We will walk through a sample analysis.
-
Explore the outputs!
Alternative Pathway analysis tools and strategies!
At this point, to generate additional visualizations and gain more insight from our enrichment analysis, we can turn to two powerful functions in the clusterProfiler package: gseGO and enrichKEGG. These tools allow us to go beyond simply identifying enriched pathways and give us the ability to visualize and explore these pathways in a much more detailed way.
First, to use gseGO and enrichKEGG effectively, we need a ranked list of DE genes based on their log2 fold change values. This ranked list allows us to analyze and visualize enrichment based on the degree of differential expression, rather than just a binary presence or absence in a pathway.
# Create a named vector of log2 fold changes with Entrez IDs as names
ranked_genes <- setNames(DE_genes_clean$log2FoldChange, DE_genes_clean$entrez)
# Sort the genes by log2 fold change
ranked_genes <- sort(ranked_genes, decreasing = TRUE)
Using gseGO, we can analyze the ranked DE genes list to create classic GSEA enrichment plots. These plots help us see how gene expression levels are distributed across the pathways that were identified as significant in our initial analysis. By examining the ranking of gene expression within these pathways, we can get a clearer picture of how specific pathways are activated or suppressed in our data set.
# Install a package missing from the template
#if (!requireNamespace("BiocManager", quietly = TRUE))
# install.packages("BiocManager", quiet = TRUE)
#BiocManager::install("pathview", update = FALSE, ask = FALSE, quiet = TRUE)
# Load relevant packages
library(enrichplot)
library(clusterProfiler)
library(pathview)
library(ggnewscale)
library(ggplot2)
gsea_res <- gseGO(
geneList = ranked_genes, # Ranked list of genes
OrgDb = org.Hs.eg.db, # Specify organism database
ont = "CC", # Use "BP" for Biological Process, "MF" for Molecular Function, "CC" for Cellular Component
keyType = "ENTREZID", # Ensure your gene IDs match the key type in OrgDb
pvalueCutoff = 0.05, # Set a p-value cutoff for significant pathways
verbose = TRUE
)
Generate the classic GSEA enrichment plot
# Plot the enrichment plot for a specific GO term or pathway - Synapse
gsea_plot <- gseaplot(gsea_res, geneSetID = "GO:0045202", title = "Enrichment Plot for Synapse")
ggsave("gsea_go_synapse_plot.pdf", plot=gsea_plot, width = 8, height = 8)
We can use additional visualizations, such as dot plots, ridge plots, and concept network plots, to gain further insights into the enriched pathways.
# Dotplot for top GO pathways enriched with DE genes
gsea_dot_plot <- dotplot(gsea_res, showCategory = 30) + ggtitle("GSEA Dotplot - Top 30 GO Categories")
ggsave("gsea_dot_plot.pdf", plot=gsea_dot_plot, width = 8, height = 8)
#Ridgeplot for top GO pathways enriched with DE genes
gsea_ridge_plot <-ridgeplot(gsea_res)
ggsave("gsea_ridge_plot.pdf", plot=gsea_ridge_plot, width = 8, height = 8)
# Concept network plot to illustrate relationships between the top enriched GO terms and DE genes
gsea_cnetplot <- cnetplot(gsea_res, foldChange = ranked_genes, showCategory = 10)
ggsave("gsea_cnetplot.pdf", plot=gsea_cnetplot, width = 8, height = 6)
The enrichKEGG function can be used to visualize KEGG pathways, showing detailed diagrams with our DE genes highlighted. This approach is especially useful for understanding the biological roles of up- and down-regulated genes within specific metabolic or signaling pathways. By using the pathview package, we can generate pathway diagrams where each DE gene is displayed in its functional context and color-coded by expression level. This makes it easy to see which parts of a pathway are impacted and highlights any potential regulatory or metabolic shifts in a clear, intuitive format. We will start by downloading and installing the KEGG database and then run the enrichKEGG function.
# Download KEGG DB file and install
download.file('https://www.bioconductor.org/packages/3.11/data/annotation/src/contrib/KEGG.db_3.2.4.tar.gz', destfile='KEGG.db_3.2.4.tar.gz')
install.packages("KEGG.db_3.2.4.tar.gz", repos = NULL, type = "source")
# Run enrichKEGG with local database option
pathways <- enrichKEGG(gene = names(ranked_genes), organism = "hsa", keyType = "kegg", use_internal_data=TRUE)
head(pathways@result)
Let’s choose one of the pathways above, for example hsa04010 - MAPK signaling pathway to visualize.
# Define the KEGG pathway ID based on above, and run pathview (note this automatically generates and saves plots to your current directory)
pathway_id <- "hsa04010" # Replace with the KEGG pathway ID of interest
pathview(
gene.data = ranked_genes, # DE gene data with Entrez IDs
pathway.id = pathway_id, # KEGG pathway ID
species = "hsa", # Species code for human
limit = list(gene = c(-2, 2)), # Set color scale limits for log2 fold changes
low = "blue", # Color for down-regulated genes
mid = "white", # Color for neutral genes
high = "red" # Color for up-regulated genes
)
#To exit R type:
quit(save = "no")